
The Internet Control Message Protocol or ICMP is a transport layer protocol used in TCP/IP networking environments. It is a supporting layer protocol that is used to relay information about connectivity issues or failures in the Internet protocol suite. Therefore, it can be said that the protocol enables TCP/IP to handle errors as all network devices that use TCP/IP have the capability to send, receive or process ICMP messages.
This means network connectivity devices, like routers and switches, also use ICMP to send error messages back to the source devices querying about or using, compromised transmissions.
For example, when a computer sends out a traceroute command, any ICMP errors – like offline devices – are directed back to the source IP address of the querying computer.
Don’t worry; we will have a detailed look at how all this works in a bit.
ICMP is in the same transport layer as IP
We need to take time out here and remind you that ICMP packets are transported over networks in the Data portion of an IP packet.
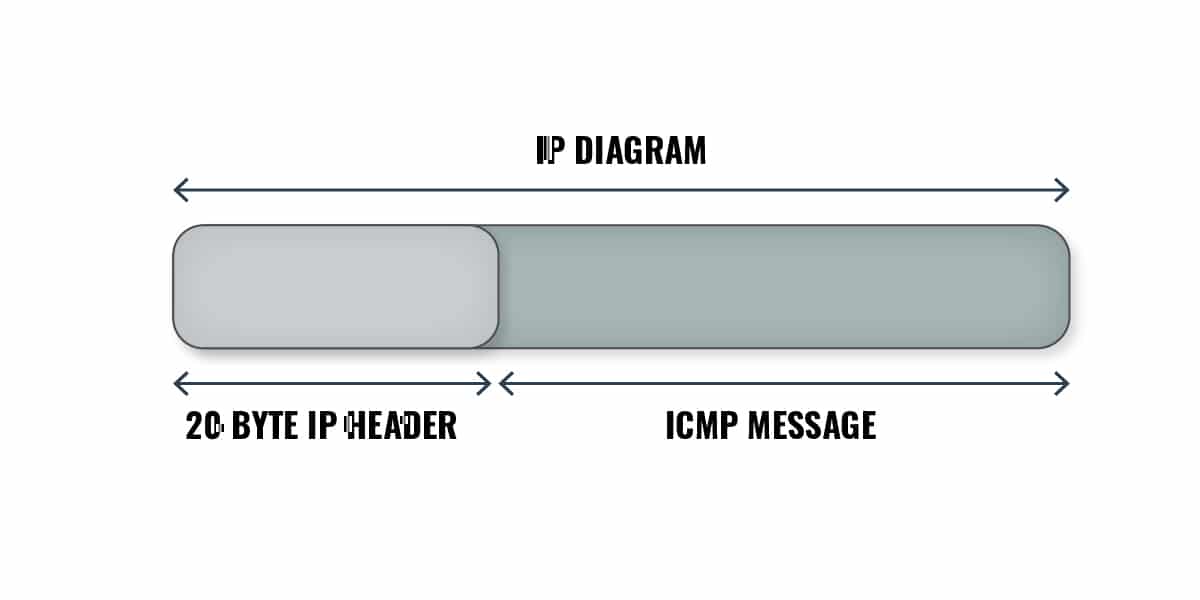
And yet, although ICMP messages are transported by IP, the ICMP protocol is considered to be at the same level as the IP Protocol – which is in the Network Layer of the OSI Model of Computer Networking.

OSI Model 7 Layers
In the ICMP header we find three fields:
Unchanged:
-
- Type – an 8-bit field that defines the ICMP message type
- Code – an 8-bit field that defines the subtype of the ICMP message
- Checksum – a 16-bit security field used to verify that the message being sent is correct and hasn’t been tampered with
Unchanged:
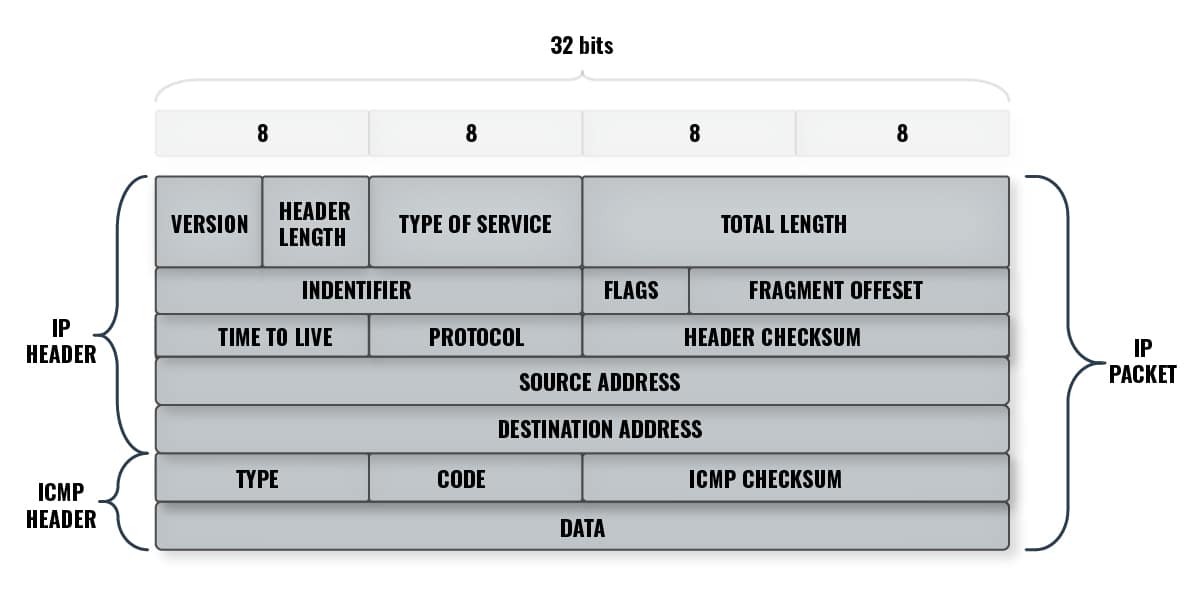
Note that, in the diagram above, the IP and ICMP Headers are both subsets of the whole IP Packet – meaning, the ICMP packet piggybacks on the IP address packet.
Protocol Number 1 – ICMP
ICMP is such an important protocol that the Internet Assigned Numbers Authority (IANA) – the authority overlooking “the global coordination of the DNS Root, IP addressing, and other Internet protocol resources” – has assigned it “Protocol Number 1” making it only second in importance after Protocol Number 0: HOPOPT (an IPv6 Hop-by-Hop Option).
ICMP error message types
ICMP error messages are divided into two categories: error-reporting messages and query messages.
Examples of error messages are:
| Error type no. | Text Description |
|---|---|
| 3 | Destination unreachable |
| 4 | Source quench |
| 5 | Redirection |
| 11 | Time exceeded |
| 12 | Parameter problem |
Examples of query messages are:
| Query and Reply type no. | Text description (Query) | Text description (Reply) |
|---|---|---|
| 0 and 08 | Echo | Echo Reply |
| 09 and 10 | Router Solicitation | Router Advertisement |
| 13 and 14 | Timestamp | Timestamp Reply |
| 17 and 18 | Address Mask Request | Address Mask Reply |
Just to put it in perspective, the PING utility tool is implemented using the ICMP Echo request (Type 0) and Echo reply (Type 8) messages.
Why was ICMP necessary?
The main reason for the existence of a protocol like ICMP is because TCP/IP does not have an in-built mechanism that sends out (and receives) messages for querying, control, and reporting communication errors. In real life, ICMP offers error control and often it is employed to report errors, send management queries, and operations information.
But, we shouldn’t assume that a reply message is only triggered if a query (or control) command is sent from an origin device because an event can trigger an ICMP message too.
The case in hand would be a Source Quench request. Let’s see what that means:
Let’s say we have Computers “A” and “B” that are in constant communication with one another. And suppose Computer “A” was sending too many queries to Computer “B” – which is struggling to handle the replies.
Now, a Source Quench request is sent by Computer “B” in a bid to tell Computer “A” that it needs to decrease the rate of the queries it is sending. The triggering reason may be that Computer “B” does not have sufficient buffer space to process Computer “A’s” incoming requests. Or perhaps its buffer is approaching its capacity limit.
It, therefore, sends out a message telling the Computer “A” to take it easy on it before a freeze or, worse, a crash occurs.
ICMP and TCP/IP and PING
PING is a network diagnostics tool that we use to find out:
- Whether a device is up and running or not
- If there is a communication between two devices
- The identity or description of a remote device
The PING command sends out an ICMP echo request. This is replied to by the host or targeted device using an ICMP echo reply. This means that, while a PING runs using ICMP protocol, it is not itself an ICMP protocol.
Trivia: Did you know that PING was named after the submarine act of “pinging” another vessel using sonar? A backronym – yes, that’s a proper word – was later created for it: “Packet InterNet Groper.”
When the late Michael John Muuss wrote the PING utility in 1983, it was a reliable indicator of a node’s status on the older Internet – when firewalls were rare or didn’t even exist at all.
But, on today’s networks, it has become a “fairly reliable” diagnostic tool. For instance, an unanswered PING – an ICMP Echo Request with no Echo Reply – does not necessarily mean that a host is down. It could, for example, be that the Echo Request or Echo Reply may have been blocked or filtered on the responding device. This is a common activity these days because, as we will see, hackers can use ICMP to scope out their target networks or even bring them down. That is why some administrators configure their routers to ignore Echo Request and Echo Reply ICMP packets.
ICMP and TCP/IP and traceroute
The traceroute or tracert command is one of the most popular network diagnostics tools. It is easy to run, light on resources, and can give useful feedback.
It uses the ICMP Time Exceeded message to map out a network route – hop by hop.
Here’s how it works:
An administrator sends out a traceroute command addressed to a computer that is on the other side of the world, let’s say. The sent packet includes data like the source and destination IP addresses as well as a TTL (Time To Live) indicator or flag.
- The first Packet sent (P1) goes to the first device in the route with a TTL of 1.
- The device, let’s say it is a router (R1), accepts the packet, subtracts 1 from the TTL making it 0.
- If the deducted TTL were greater than 0, R1 would have forwarded it on to R2 the next router in the network; but since it is 0, it drops the packet, and Echo Replies back to the initial machine informing it about this decision to drop the packet.
- The administrator receives the reply and his computer extracts information like the name, IP address, and RTT that is included in the replying packet and displays it.
- If the intended device has not been reached, a second Packet (P2) is sent out with a TTL of 2. As we have seen above, R1 subtracts 1 from the TTL and forwards P2 (with TTL 1) to the next connecting device, i.e. R2, which also subtracts one from TTL, realizes it is now a TTL of 0, drops the packet and Echo Replies back to the source device with this information.
- This process keeps repeating until the final device – the destination host is contacted.
Therefore, the TTL field is used to avoid routing loops – every time a packet passes through a router, the router decrements the TTL value by 1. If the TTL reaches 0 before the targeted destination host is “hopped,” the router drops the packet and sends an ICMP Time Exceeded message back to the original sender. This is like saying, “I couldn’t reach the device within the allocated TTL – which is defaulted to 30 hops.”
And so, this is all repeated over and over 30 times or until the addressed device is reached – or not depending on the number of hops and whether the device can be located – following which the traceroute command exits.
Note: We will see what routing loops are in a bit. For now, just think of it as a packet bouncing back and forth – non-stop – between two routers.
In the end, the administrator will be able to see the number of hops to the destination server, the round-trip times (RTTs) for each hop, and the name and IP addresses of the devices along the route.
Finally, we need to remember that the protocol used for traceroute isn’t always ICMP. While Windows uses ICMP echo requests, UNIX-like operating systems use UDP packets – but, the response is always sent back using ICMP protocol, regardless of the operating system.
A little bit about the error messages returned by ICMP
We have seen that the ICMP protocol is used for message transport, reply, and communication over a network. We have also seen a few examples like:
- Echo Request and its corresponding Echo Reply are used in PING
- An overflow of packets is addressed using the Source Quench message to slow down the rate of incoming data traffic to prevent a looming crash or packet loss
- A Destination Unreachable message indicates that a destination device is, well, unreachable
- Changed routes are announced using a Redirect message
But, there’s more…
Request timed out
The result of a trace to singingdetective.com where the 11th hop isn’t responding – whether because it is intentionally configured to do so, or not – and triggered a “Request timed out,” would look like this:

This is different from the routing loop we mentioned earlier. Let’s have a look at that now…
Routing loops
A routing loop occurs when routers – which are usually misconfigured – pass packets to one another in a continuous, non-ending loop.

In the example above, the ICMP packets are being looped around between router 219.93.218.177 and router 10.55.41.129 – and with routers 10.64.4.205 and 10.55.41.128 thrown into the looping mix. This is what is known as a routing loop.
The fallout from such a routing loop is:
- Packets that you can’t get rid of forever – while ICMP packets will get dropped after the maximum number of hops has been reached (remember: the default is 30), there are protocol packets that will continue to ping around in the loop forever; a good example is Exterior Gateway Protocol (EGP), a routing protocol commonly used between hosts on the Internet to exchange routing table information
- Over-consumption of bandwidth – as the number of the packets that are ping-ponging between the routers increases, the network’s performance will start to depreciate; this issue could grow out of control and affect the whole network’s performance
- Unreachable hosts – any traceroute packets sent over this network will fail to reach their destinations; communication will be near impossible if packets have to rely solely on these routers
Of course, there are networking methods and tricks that can be implemented to prevent routing loops from occurring in the first place. Examples are Holddown timers and split horizons.
The ICMP rules
As useful as the ICMP protocol is, there are some important rules that it must abide by. There are also rules that are imposed on the protocol to make sure that it doesn’t negatively affect a network’s performance.
Here are a few examples:
- No special priority – ICMP has no special privileges and has to pass on as a “lowly” packet; this is just to make sure that a flood of ICMP packets won’t slow a network down
- No self-replying – an ICMP reply message can’t be sent in response to an ICMP query message; in fact, no ICMP message can be sent as a response to another one because this would create a non-stop back-and-forth of ICMP messages creating an ICMP message, creating an ICMP… and so on, ad infinitum…
- No response to multiple traffic – an ICMP message can’t be sent in response to traffic that comes from multicasts, broadcasts, loopbacks, or invalid addresses
- No guarantee of delivery – as we have seen in examples above, some administrators might consider them to be a nuisance and configure their devices to ignore or even block them; this means the packets could end up lost or dropped making it a rather unreliable diagnosis tool
With all this being said, every precaution has been taken to make ICMP a safe, useful protocol that can be an effective tool in network issue troubleshooting. But, unfortunately, there are still ways it can be abused, as we shall see next.
The malicious side of ICMP
Believe it or not, hackers can use ICMP packets to wreak havoc on your network. One way of doing this is by launching a Distributed Denial of Service (DDoS) attack. They can use three ways to cripple – or even crash – your network:
- ICMP flood attack – here the attacker will try to send so many pings at your device until it can no longer handle all the ICMP echo request messages that are being sent its way; the sheer amount of processing power required to handle the requests alone will hog all the resources making it impossible for the device to stay online, let alone do anything else
- Ping of Death attack – in this case, the attacker will send an extremely large ping to a device that can’t handle it with the intention of freezing (or even crashing) it due to buffer overflows
- Smurf Attack – in this attack, ICMP packets that have fake or spoofed IP addresses (of the intended victim) are sent to another device or server with a broadcast IP address; when the broadcasted ICMP echo replies are sent from the devices on the other side of the broadcast, they will bombard the victim’s server because that is the IP address they will be forwarded to
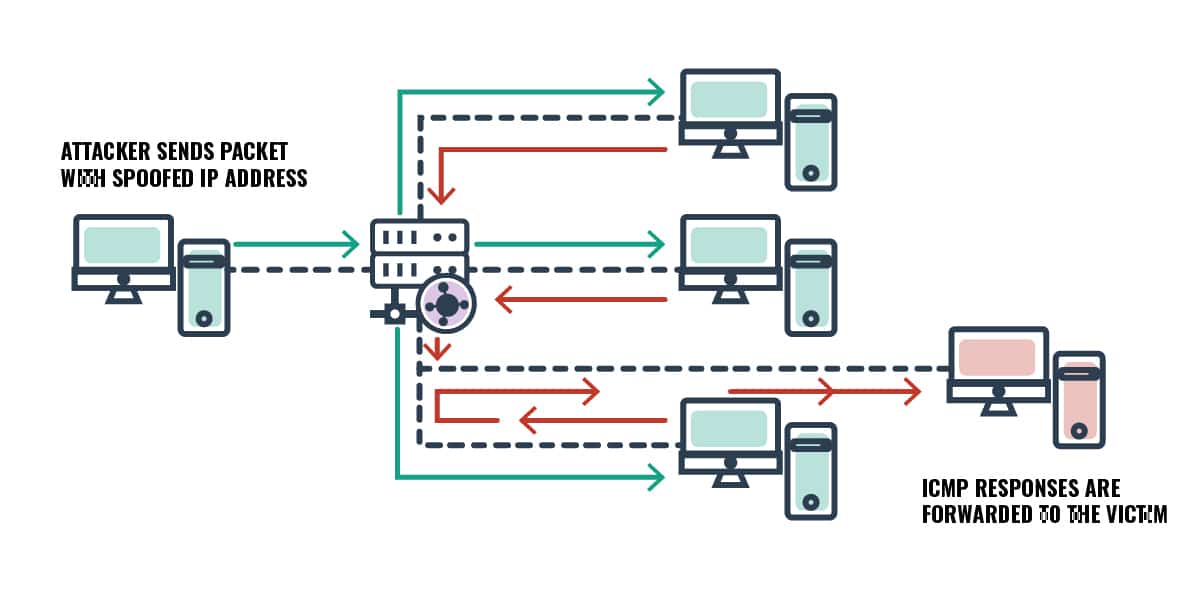
Modern networks and online devices are much more robust, have huge processing powers, and have been made to resist these sorts of malicious attacks. But, that doesn’t mean the attacks haven’t occurred – and will probably continue to occur – in recent times.
That’s all about ICMP
And there you have it; you now have a clear picture about ICMP and all the wonderful things it can do to help troubleshoot network issues.
Let us know your thoughts about this amazing protocol. Leave us a comment below.


